EDA란 ?
데이터 그 자체만으로부터 인사이트를 얻어내는 접근법 !
EDA의 Process
1. 분석의 목적과 변수 확인
- 분석의 목적을 정확히
- 데이터 타입이 분석하는 데에 적절한지
2. 데이터 전체적으로 살펴보기
- 데이터간의 상관관계는 없는지
- 데이터의 결측치는 없는지
- 데이터의 사이즈가 적절한지( 데이터의 사이즈가 너무 작은 경우)
3. 데이터의 개별 속성 파악하기
- 데이터의 속성이 적절히 매칭되어 있는지
EDA with Titanic Data
0. 라이브러리 준비
# 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline# 동일 경로에 "train.csv"가 있을 때
# 데이터 불러오기
titanic_df = pd.read_csv("./train.csv")1. 분석의 목적과 변수 확인
I. 분석의 목적 확인
> 살아남은 사람들은 어떤 특징을 가지고 있었을까? II. 변수 확인

- Variable : column name
- Definition : 각 column에 대한 정보
- Key : 숫자로 encoding 되어 있는 경우, 각 숫자가 무엇을 의미하는지
2. 데이터 전체적으로 살펴보기
2.0 전체 데이터 프레임
titanic_df.head(5)
2.1 각 Column의 데이터 타입 확인하기
titanic_df.dtypes
2.2 데이터 전체 정보를 얻는 함수 : .describe()
titanic_df.describe() # 수치형 데이터에 대한 요약만을 제공 !
데이터의 결측치는 없는지, 이상치는 없는지 살펴보기
2.3 상관계수 확인 !
titanic_df.corr()
절대값이 큰 값을 보며 살펴보기
Correlation is NOT Causation
상관성 : A up, B up, ...
인과성 : A -> B
2.4 결측치 확인
titanic_df.isnull().sum()
Age, Cabin, Embarked에서 결측치 발견
3. 데이터의 개별 속성 파악하기
I. Survived Column
# 생존자, 사망자 수는?
titanic_df["Survived"].sum() # 생존자만
titanic_df["Survived"].value_counts() 
## 생존자수와 사망수를 Barplot으로 그려보기 sns.countplot()
sns.countplot(x="Survived", data=titanic_df)
plt.show()
II. Pclass
# Pclass에 따른 인원 파악
titanic_df[["Pclass", "Survived"]].groupby(["Pclass"]).count()
# Pclass에 따른 생존자 인원 파악
titanic_df[["Pclass", "Survived"]].groupby(["Pclass"]).sum()
# Pclass에 따른 생존 비율
titanic_df[["Pclass", "Survived"]].groupby(["Pclass"]).mean()
# 히트맵 활용
sns.heatmap(titanic_df[["Pclass", "Survived"]].groupby(["Pclass"]).mean())
plt.show()
III. Sex
titanic_df.groupby(["Sex", "Survived"])["Survived"].count()
sns.catplot(x="Sex", col="Survived", kind='count',data=titanic_df)
plt.show()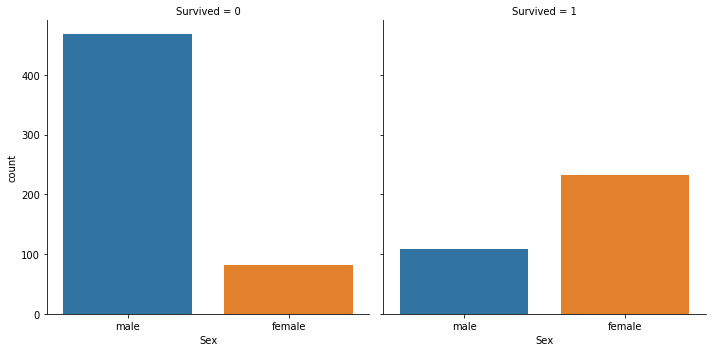
IV. Age
Remind : 결측치 존재 !
titanic_df.describe()['Age']
# Survived 1, 0과 Age의 경향성 파악
fig, ax = plt.subplots(1,1,figsize=(10,5))
sns.kdeplot(x=titanic_df[titanic_df.Survived == 1]['Age'], ax=ax)
sns.kdeplot(x=titanic_df[titanic_df.Survived == 0]['Age'], ax=ax)
plt.legend(["Survived", "Dead"])
plt.show()
나이가 많거나 어린 분들은 생존율이 높았고, 중간 나이대 분들은 생존율이 낮았다.
Appendix I. Sex + Pclass vs Survived
sns.catplot(x="Pclass", y="Survived", kind="point", data=titanic_df)
plt.show()
sns.catplot(x="Pclass", y="Survived", hue="Sex", kind="point", data=titanic_df)
plt.show()
단일 변수로 보이지 않던 사실이 복합 변수를 통해 보여진다.
Appendix II. Age + Pclass
## Age graph with Pclass
titanic_df["Age"][titanic_df.Pclass == 1].plot(kind="kde")
titanic_df["Age"][titanic_df.Pclass == 2].plot(kind="kde")
titanic_df["Age"][titanic_df.Pclass == 3].plot(kind="kde")
plt.legend(["1st class", "2nd class", "3rd class"])
plt.show()
각 그래프의 중심이 오른쪽으로 이동함. 클래스가 높아질 수록 나이대도 높아짐.